
감사합니다.
무료 접속 서버를 통해서 Propensity score matching을 하였습니다.
nearest 방법을 사용했고
caliper를 0.25, 0.2, 0.1 여러 방법으로 해보았고
discord both, caliper 0.1이 SD가 제일 좋게 나와
이대로 분석을 사용하려고 합니다.
세가지 질문이 있는데요
1. caliper 0.25, 0.2, 0.1들은 정확히 어떤 의미인가요?
차이가 어떻게 되는지 이해가 잘 안됩니다.
숫자마다 통계적 우위가 있는지도 궁금합니다.
2. 의학논문을 쓰고 있습니다. IF가 굉장히 높은 유명 저널(JAMA, Lancet, Nejm)에서는 standard deviation을 모두 밝히고 0.1 이하인걸 table에 제시하던데
그외 대부분의 의학 논문에는 SD를 표시하지 않더라구요.
모든 covariate에 대해 SD가 반드시 0.1이하여야 의미가 있는건가요?
아니면 1~3개 정도는 0.1 이상이여도 괜찮은건가요?
3. 이 프로그램을 쓴걸 인용해야할꺼 같은데 추후에 SCI급 외국 저널에 submission시킬 계획인데
인용은 어떤식으로 하면 되는지 궁금합니다.
감사합니다.
Comment 7
-
cardiomoon
2021.02.18 22:01
-
정지윤
2021.02.19 16:39
답변 감사합니다.
2번에 대해서 추가 질문좀 드리겠습니다.
multicovariate에 대해 PSM을 할때 해당 covariate에 대해 전부 0.1이하여야 그 method를 쓸수 있는건가요?
제가 돌린 PSM에서 10개의 covariate 중 2개가 SMD -0.273, -0.195로 report에서
so we tried 1:1 nearest matching on the propensity score without replacement, which yielded inadequate balance, as indicated in Table and Figure. After matching, standardized mean differences for the covariates BMI and Extent were above 0.1 indicating poor balance
라고 확인되었으면, 모든 covariate에 대해 0.1이하 만족할때까지 여러 method를 찾아야하는건가요?
아니면 이정도는 감안하고 그대로 사용해도 되는건지 궁금합니다.
아래는 제가 돌린 PSM의 love plot입니다. 두가지 covariate에 대해 imbalance하더라구요.
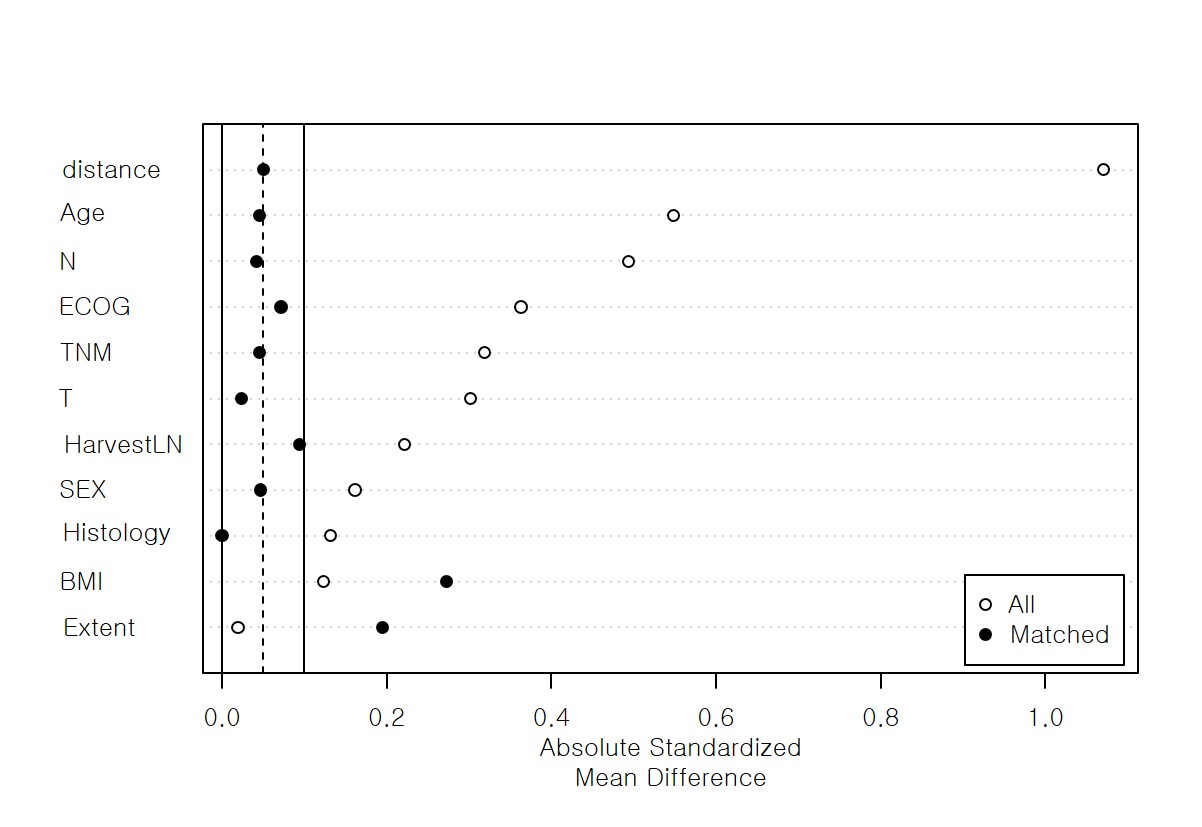
첫 글에서 언급한대로. 실제로 대부분의 의학논문이 이 SMD 값을 제시하지 않고 PSM했다는 내용만 제시하여 검증이 정확했는지 확인을 못하더라구요.
이정도 balance로 진행해도 무방한지 궁금합니다.
-
cardiomoon
2021.02.19 16:46
full matching 을 해보실것을 추천드립니다
-
정지윤
2021.02.20 10:43
Full matching으로 여러 setting으로 돌려보았는데 더 많은 imbalance만 관찰되었습니다.
위 nearest로 한 결과에 대해 BMI와 Extent 두가지 covariate의 imbalance를 감안하고 사용해도 될까요?
아니면 모든 covariate에 대해 SMD 0.1이하여야하는 것이 필수 조건인가요?
-
cardiomoon
2021.02.22 22:46
답변이 늦어 죄송합니다. Optimal matching을 해보실 것을 권해드립니다. 또한 최근 propensity score matching에 관한 좋은 책이 한권 출간되었습니다. 제가 쓴 책은 아니지만 "R기반 성향점수분석(백영민, 박인서)" 책을 참고하셔요
-
정지윤
2021.02.24 22:17
optimal matching 포함하여 다른 종류의 matching가 여러 caliper를 시행해보았으나, 위 분석이 가장 balance가 좋았습니다.
이럴 경우에 제가 했던 분석을 채택해도 되는건가요?
-
cardiomoon
2021.02.25 12:17
보통 논문에서는 SMD 기준을 0.1 또는 0.25를 많이 씁니다. 어떤 기준을 정하는가는 연구자의 몫인것 같습니다.
안녕하세요? 제가 만든 PSM앱을 사용하셨다니 반갑습니다. 제가 PSM에 관한 R 패미지 및 앱을 개발하고 있는 이유는 바로 선생님처럼 훌륭한 논문을 쓰실 때 도움이 되기위해서입니다.
1. caliper 문제는 다음을 참조하십시요.
https://cran.r-project.org/web/packages/MatchIt/vignettes/matching-methods.html
2. PS matching 이 잘 되었는지 여부는 SD가 아니라 balance를 체크해봐야 합니다. 다음 문서를 참조하십시요.
https://cran.r-project.org/web/packages/MatchIt/vignettes/assessing-balance.html
이때 가장 중요한 것이 standardized mean difference가 모두 0.1 또는 0.05 이하여야 합니다. 만약 그렇지 않은 경우 nearest가 아닌 다른 방법(full matching등)을 고려하여야 합니다.
3. 인용할 때는 R 4.0.3 및 MatchIt 패키지를 인용해주십시요. 조만간 제가 만든 webrPSM패키지를 CRAN에 등록한 후에는 제 패키지를 인용하셔도 됩니다.
To cite MatchIt in publications use:
Daniel E. Ho, Kosuke Imai, Gary King, Elizabeth A. Stuart (2011). MatchIt: Nonparametric
Preprocessing for Parametric Causal Inference. Journal of Statistical Software, Vol. 42, No.
8, pp. 1-28. URL https://www.jstatsoft.org/v42/i08/
A BibTeX entry for LaTeX users is
@Article{,
title = {{MatchIt}: Nonparametric Preprocessing for Parametric Causal Inference},
author = {Daniel E. Ho and Kosuke Imai and Gary King and Elizabeth A. Stuart},
journal = {Journal of Statistical Software},
year = {2011},
volume = {42},
number = {8},
pages = {1--28},
url = {https://www.jstatsoft.org/v42/i08/},
}